基于特征图像生成的Android恶意软件检测方法
关键词:特征向量分类器分类
陈 非,曹晓梅,王少辉
(南京邮电大学 计算机学院、软件学院、网络空间安全学院,江苏 南京 210003)
0 引 言
近年来,Android操作系统在中国的市场份额不断提高,其在2021年第四季度的市场份额已经达到78%[1]。然而,Android操作系统的飞速发展不仅带来市场份额的提高,也带来许多安全问题。360发布的《2021年度中国手机安全状况报告》[2]显示,360安全大脑在2021年共截获移动端新增恶意软件样本约943.1万个,平均每天截获新增手机恶意软件样本约2.6万个。不法分子利用Android应用植入广告、窃取隐私,严重威胁用户的财产和隐私安全,设计合理可行的Android恶意软件检测方法至关重要。
传统的Android恶意软件检测方法包括三种:基于静态分析、动态分析以及机器学习的检测方法。基于静态分析的方法[3-5]通过提取签名、权限、组件等特征,生成特征匹配字典,将未知应用的特征与字典进行匹配,根据得到的相似度判定是否属于恶意软件。静态分析方法操作简单,但检测类型单一、误报率较高。基于动态分析的方法[6-9]是指在沙盒或虚拟机运行Android应用程序,通过监听和分析应用程序在运行过程中行为和运行状态的变化,如系统调用事件、潜在的劫持行为、数据流等,判断是否属于恶意软件。动态分析方法准确率高于静态分析方法,但动态分析方法需要运行应用程序,分析所需要的时间较长。基于机器学习的检测方法通过对大量的样本提取特征和训练,生成分类模型,从而实现对恶意软件的检测。SVM、KNN、随机森林、Stacking等传统机器学习算法已经被应用到Android恶意软件的检测中[10-13],并且检测准确率相较于基于静态分析和动态分析的方法有了较大提高,但基于机器学习的检测方法存在特征分布不平衡、难以挖掘特征之间深层联系等问题,限制了其准确率的进一步提高。
相比于传统机器学习,深度学习具有自适应提取特征和挖掘特征深层联系的优势,此优势也是深度学习能够在图像分类、文本预测等方面成功实践的原因所在。针对传统机器学习检测Android恶意软件存在的问题,结合深度学习的优势和成功实践,深度学习应用到Android恶意软件检测可以取得较好的结果。目前,深度学习算法[14-19]在Android恶意软件检测中已有应用,且取得了一定成果,但仍存在不足:(1)用于分类模型训练的数据表征能力偏弱,制约模型的收敛速度和检测精度;(2)检测不同类别相似度较高的样本时,存在较大的漏报数和误报数,导致算法最终的检测准确率降低。
针对不足之处,该文提出一种基于特征图像生成的Android恶意软件检测方法(Android Malware Detection Method Based on Feature Image Generation,FIG-AMD)。FIG-AMD方法针对训练数据表征能力偏弱的问题,提取APK文件的权限、API、操作码作为特征,挖掘各自的频繁特征项集,使用降噪自编码器(Denoising Autoencoder,DAE)抽取信息和转换维度,将经过DAE处理的各特征进行融合,生成RGB特征图像。该方法生成的特征图像融合了多种特征,具有更好的表征能力。针对难以检测相似度较高样本的问题,该文设计了BaggingCNN分类算法,BaggingCNN使用 Bootstrap抽样构造子训练集,并训练基于Bagging的多个CNN分类器用于检测Android恶意软件。实验证明,FIG-AMD方法可以有效对Android恶意软件进行检测,且有着较低的误报率。
1 相关工作
Imtiaz等人[14]提出DeepAMD恶意软件检测模型,该模型主要使用人工神经网络(Artificial Neural Network,ANN)构建,选取权限、API、Intent Filter作为特征,尽管实验表明该模型的检测性能优于多数机器学习模型,但文中取得的二分类的准确率(93.40%)仍然偏低,主要原因是ANN存在梯度消失或梯度爆炸的问题,降低了检测模型的拟合程度。超凡等人[15]提取APK文件应用组件、Intent Filter、权限等特征,并使用遗传算法进行特征选择以降低维度,最后使用深度神经网络(Deep Neural Network,DNN)进行分类检测,该方法提取的特征很充分,但提取的特征维度较高,增加了特征筛选的时间开销。Elayan等人[16]使用API调用和权限作为特征,使用循环神经网络(Recurrent Neural Network,RNN)中的门控循环单元(Gated Recurrent Unit,GRU)进行分类检测,该方法虽然准确率等指标很高,但训练模型使用的数据集数目较少,存在泛化能力弱的问题。孙志强等人[17]提出一种基于深度收缩降噪自编码网络的检测方法,使用权限、API 等作为特征,使用贪婪算法自底向上训练每个收缩降噪自编码网络,以抽取原始特征信息,最后使用反向传播算法进行训练和分类,该方法检测效果优异,但缺少对重要特征的筛选,会增加分类模型的训练时间。Xiao等人[18]针对现有检测方法存在的数据模糊、代码覆盖范围有限的问题,直接从Dalvik字节码(classes.dex)中学习恶意软件的特征,生成RGB图片并使用卷积神经网络(Convolutional Neural Network,CNN)进行分类检测,该方法检测时间远低于其它方法,但缺少对敏感特征的关注,导致图像的表征能力偏弱,进而影响了CNN 模型的收敛速度和检测精度。Yen等人[19]提出基于代码重要性和可视化深度学习的检测方法,该方法根据TF-IDF计算APK文件源代码每个单词的重要值,经过分组和排序,使用Simhash和Djb2算法生成RGB图片,并使用CNN进行训练和分类,该方法特征单一且存在特征信息丢失,降低了CNN的分类性能 。
与同类工作相比,该文的主要贡献和创新点体现在以下三点:(1)在特征预处理方面,对APK文件的多种特征进行提取,使用改进的FPGrowth算法对提取到的特征进行挖掘,有效过滤了低频特征,提高了特征组合的合理性;(2)使用DAE抽取特征数据深层次信息和转换特征向量维度,将经过DAE处理的权限、API、操作码对应的特征向量合成为三维RGB图片作为特征图像。该方法生成的特征图像具有较好的表征能力,分类算法可以很好地从中学习到不同类别Android应用的行为特征,进而有效的识别出恶意软件;(3)分类算法对多个CNN分类器进行集成,并将Bagging算法的Bootstrap抽样方法和多数投票机制迁移到该算法,设计出BaggingCNN分类算法。该算法通过多分类器集成提升了算法的分类能力,可以有效检测出不同类别相似度较高的样本,进而算法的检测准确率、召回率、精准率均有提高。
2 FIG-AMD方法
FIG-AMD流程如图1所示,包括特征预处理、特征图像生成、BaggingCNN训练和分类三个阶段。
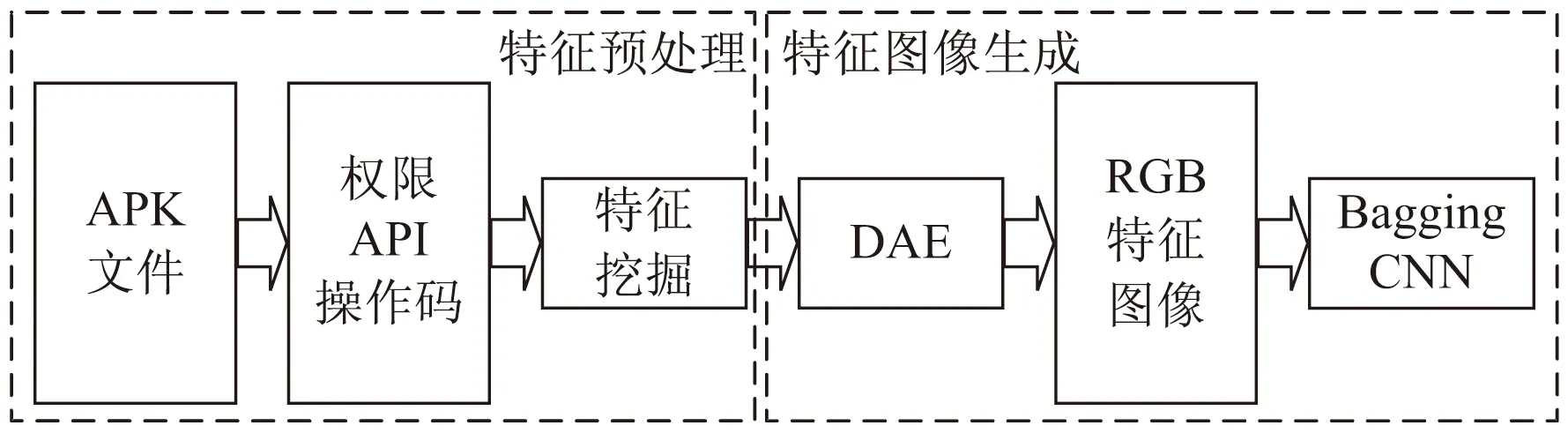
图1 FIG-AMD流程
特征预处理阶段提取APK文件的多种特征并对特征进行挖掘;特征图像生成阶段,生成RGB特征图像用于训练和分类;BaggingCNN训练和分类阶段,对生成的特征图像进行训练,调整优化算法参数,并对算法进行测试。
2.1 特征提取
该文使用特征匹配的方法对APK文件的权限、API、操作码进行提取,其流程如图2所示。使用Google提供的开源工具apktool反编译APK文件得到两种类型的文件,从Xml文件提取权限特征,从Smali文件提取API特征和操作码特征,各特征提取步骤如下所述:
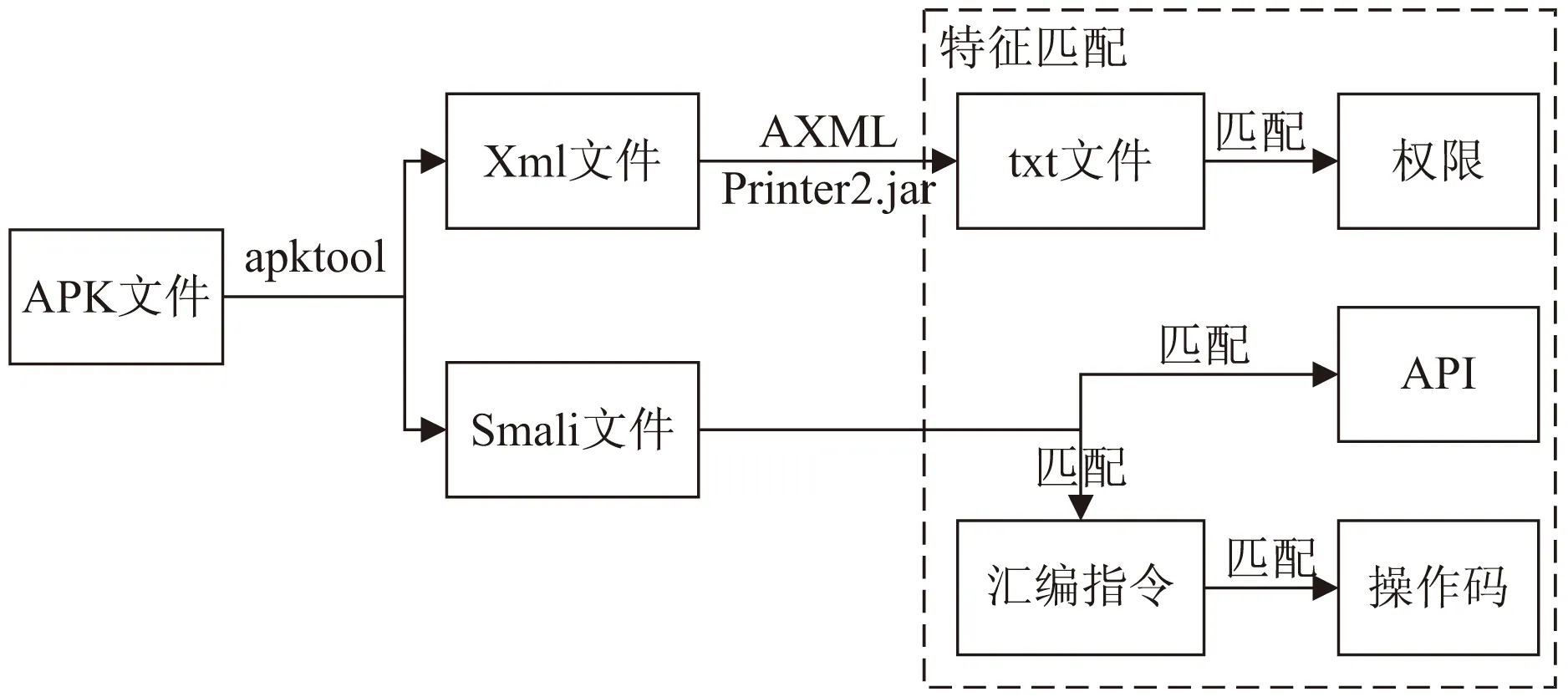
图2 特征提取方法基本流程
(1)权限:首先将文献[20]提供的权限列表构造成权限匹配字典;再利用AXMLPrinter2.jar静态工具反编译Xml文件得到txt文件;最后使用权限匹配字典对txt文件的内容进行匹配,得到相应的权限特征。
(2)API:首先将文献[20]提供的API调用列表构造成API匹配字典;再使用API匹配字典对Smali文件对应的每行语句进行匹配,得到相应的API特征。
(3)操作码:Dalvik定义了256个指令,这些指令包含move、return、invoke等基本操作码,该文根据这些指令的功能进行分类(如:move/from16、move-object/16归为M指令;goto/16、goto/32归为G指令),得到指令匹配字典。由于指令之间存在序列关系,假设其遵循马尔可夫性质并引入3-gram操作码序列。针对反编译得到的Smali文件,首先使用指令匹配字典对Smali文件的.method部分进行匹配,并将得到的指令转为相应的M、G等指令名,加入到操作码序列中;文件遍历完成后,再以3作为滑动窗口的长度提取3-gram操作码,如:{M,G,L,V}→{MGL,GLV},即得到操作码特征。
2.2 特征挖掘
FPGrowth[21]算法挖掘相关性较高的特征组合,即频繁特征项集。由于特征集合的样本个数和维度均较大,而FPGrowth算法仅适合于小规模数据集,直接使用FPGrowth算法挖掘频繁特征项集会较为耗时。因此,该文设计了基于FPGrowth算法的局部频繁特征项集挖掘方法FPGrowth-r,其实现步骤如下:
(1)将特征集合S分成k组,前k-1组每组n个特征,第k组num-n*(k-1)个特征,记第i组特征集合为Si,其中num为S的特征个数,且0
(2)使用FPGrowth算法挖掘Si的频繁特征项集(FPGrowth算法的支持度大小设置为support),得到若干个不同的频繁特征项集,取特征个数最多的项集作为Si的局部频繁特征项集,记为Gi。
(3)对k组特征集合按步骤(1)(2)进行局部频繁特征项集挖掘,得到G1,G2,…,Gk,计算Global=G1∪G2∪…∪Gk,即得到全局频繁特征项集Global。
(4)对权限、API、操作码按步骤(1)(2)(3)进行挖掘,得到各自的Global并进行过滤,最后将过滤完成的特征转为01型特征向量(1表示包含某特征项,0表示不包含)。
2.3 特征图像生成
降噪自编码器[22]在输入数据中加入了一定比例的噪声数据,从而使得DAE网络的反向传播过程迫使隐藏层学习到的特征数据具有更强的鲁棒性,进而增强了隐藏层输出数据的表征能力。因此,该文使用DAE对特征信息进行抽取和转换特征向量维度。
生成的特征图像大小为[3,w,w],即经过DAE处理后的特征向量长度为w*w,则隐藏层最后一层神经元的个数应设置为w*w。为避免DAE处理后的特征向量过于稀疏化而影响特征图像的表征能力,使用式(1)对最佳的w进行计算,即w取使得式(1)中value最小的正整数。分别对权限、API、操作码的特征向量使用DAE进行处理,DAE经过训练,损失函数值达到最小,使用式(2)计算DAE处理后的特征向量,即得到大小为w*w的特征向量。
value=|3w2-(npermission+napi+nopcode)|
(1)
(2)
RGB特征图像生成的流程如图3所示。DAE对权限、API、操作码对应的特征向量进行信息抽取和维度处理,对于同一个APK文件,其对应3个大小为w*w的线性特征向量。首先将线性特征向量转换成大小为[w,w]二维特征向量,再对各二维特征向量增加一个通道,转换成单通道图像,维度变成[1,w,w],最后将3个二维特征向量在新增的维度进行拼接,即三个特征向量分别作为RGB图片的R、G、B三个通道,其维度变成[3,w,w],得到最终的RGB特征图像。

图3 RGB特征图像生成流程
2.4 BaggingCNN分类算法
针对单一分类算法鲁棒性偏差、检测不同类别相似度较高样本误差较大的问题,设计BaggingCNN分类算法,如图4所示。BaggingCNN分类算法将不同的CNN算法根据特征图像大小重新配置网络参数和网络深度,并将这些CNN算法作为子分类器进行集成,子分类器对不同的子训练集进行训练和分类,得到若干个分类结果,根据多数投票机制得到最终的分类结果。BaggingCNN分类算法的具体实现步骤如下所述:

图4 BaggingCNN分类算法设计
(1)对于特征优化模块生成的n个RGB特征图像,该文按照一定比例将其划分成a个训练样本和n-a个测试样本,a个训练样本中包括a1个正常样本,a-a1个恶意样本。为防止随机抽取出现样本分布不平衡的问题,采用Bootstrap抽样(有放回的均匀抽样)方法,分别从正常样本中随机抽取a1/a*m个样本,从恶意样本中随机抽取(a-a1)/a*m个样本,共计m个样本。抽取共进行k轮,得到k组子训练集,每组子训练集均使用t个不同的CNN算法进行训练。
(2)t个CNN算法分别对k个子训练集进行训练,经过一定轮次的迭代更新算法参数,其分类性能达到最优,得到t*k个子CNN分类器。t*k个子CNN分类器分别对b个测试样本进行预测,每个子分类器均得到b个关于测试样本的预测结果和b个预测结果对应的概率大小。
(3)分别对t*k个CNN分类器得到的结果进行投票,1为恶意软件,0为正常软件。对于同一个测试样本得到的t*k个分类结果,若sum(CNNi[j]) ≥ceil(t*k/2),则认为该样本为恶意软件,反之则认为是正常软件。若出现票数相等的情况,则比较P1和P2的大小,P1大则认为是恶意样本,反之则为正常样本。其中,sum表示求和;CNNi[j]为第i个CNN分类器预测第j个样本的结果;ceil(t*k/2)表示CNN子分类器个数k除以2并向上取整,P1表示预测为恶意样本的平均概率,P2表示预测为正常样本的平均概率。
3 实验结果与分析
3.1 实验准备
实验环境为:Windows10操作系统,8 GB运行内存,CPU为lntel i7-7500U,GPU为NVIDIA GeForce 940MX;深度学习框架为Pytorch1.6,编程语言为Python3.7。
FIG-AMD方法的数据集分为良性样本和恶意样本。恶意样本共4 000个,其中426个来自CIC数据集、2 825个来自Drebin数据集、749个来自VirusShare数据集。良性样本共4 000个,其中1 168个来自CIC数据集,另外2 832个为笔者使用爬虫爬取的APK文件,其均经过病毒检测网站VirusTotal检测,均未发现存在风险,故标记为良性。该文将训练集和测试集按照7∶3划分,即训练集5 600个,测试集2 400个。
3.2 评估指标
针对FIG-AMD方法的评估,主要包括检测能力、学习能力和泛化能力等方面。检测能力的评估指标包括如下5个指标,其中TP、TN、FP、FN分别表示良性软件分类成良性软件、恶意软件分类成恶意软件、恶意软件分类成良性软件、良性软件分类成恶意软件的数目。
(1)准确率(Accuracy,ACC):正确检测出来的正常软件个数和恶意软件个数总和占所有软件个数的比例。
(3)
(2)良性召回率(Benign Recall,BR):正确检测出来的正常软件个数占所有良性软件个数的比例。
(4)
(3)恶意召回率(Malicious Recall,MR):正确检测出来的恶意软件个数占所有恶意软件个数的比例。
(5)
(4)误报率(False Alarm,FA):误报为良性软件的恶意软件的个数占所有恶意软件个数的比例。
(6)
(5)综合评价指标(F1):精确率(Precision)和召回率(Recall)的加权调和平均值。
良性软件的精确率:
(7)
良性软件的F1值:
(8)
恶意软件的精确率:
(9)
恶意软件的F1值:
(10)
3.3 特征预处理
将第2.2节中FPGrowth-r的n设置为10,support设置为10,表1展示了特征预处理阶段各特征的数目和不同特征挖掘方法对应的耗时情况。

表1 特征数目及特征挖掘耗时
由表1可见,使用FPGrowth和FPGrowth-r挖掘后的特征数目较为接近,两者均能对特征进行有效挖掘,但FPGrowth-r的耗时远低于FPGrowth,因此该文设计的特征预处理方法是有效的。
3.4 BaggingCNN参数
根据式(1)和表1中FPGrowth-r挖掘的特征数目,经过计算,最佳的w为16,则DAE隐藏层最后一层的神经元个数设置为256。该文使用5层的DAE网络对特征向量进行处理,最后生成大小为[3,16,16]的特征图像用于BaggingCNN训练和分类。
不同CNN算法对生成的特性图像进行分类的结果如图5所示,图中算法均根据特征图像大小调整了参数和深度,算法经过训练达到最优。BaggingCNN抽取子训练集样本个数m设置为5 600(等于训练集样本个数),为确定BaggingCNN的最优参数t和k,使用图5准确率前t的算法,在不同的抽样次数k下进行实验,结果如图6所示。
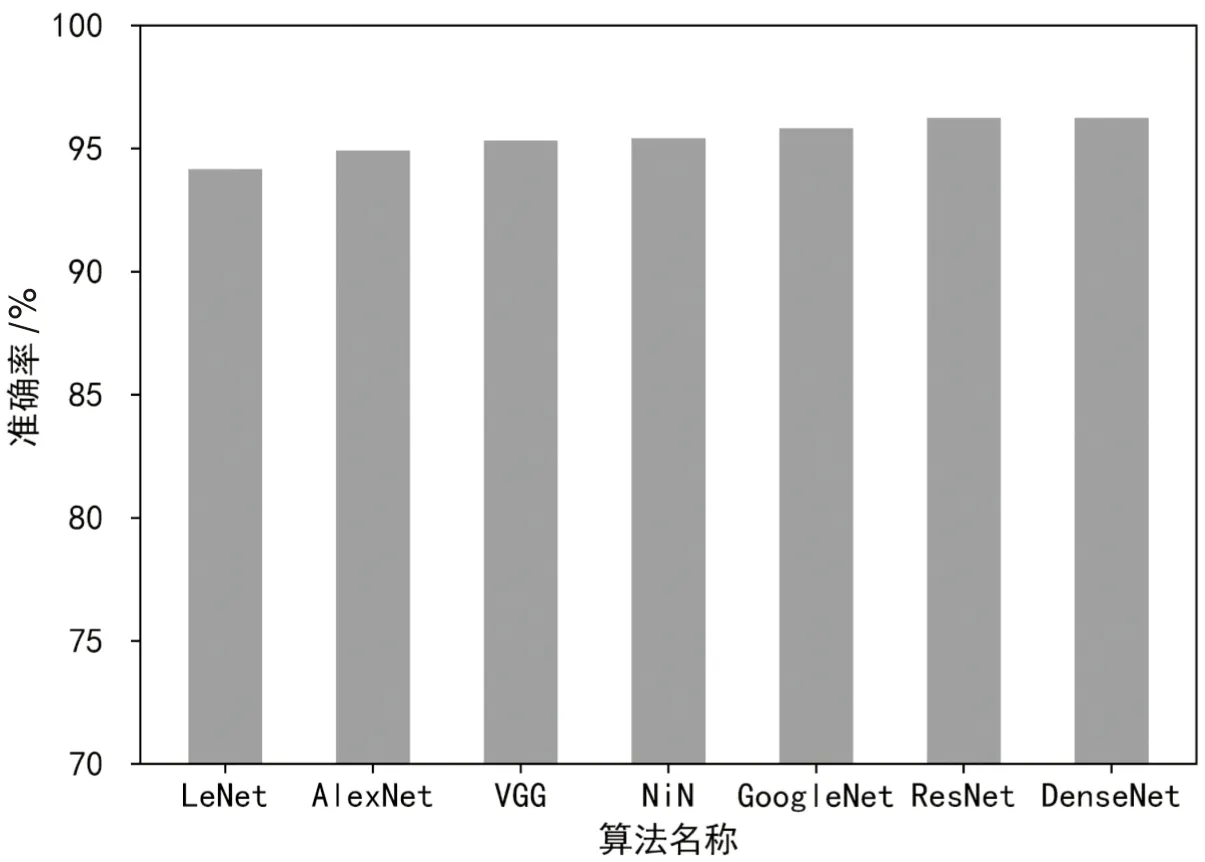
图5 不同CNN算法准确率对比
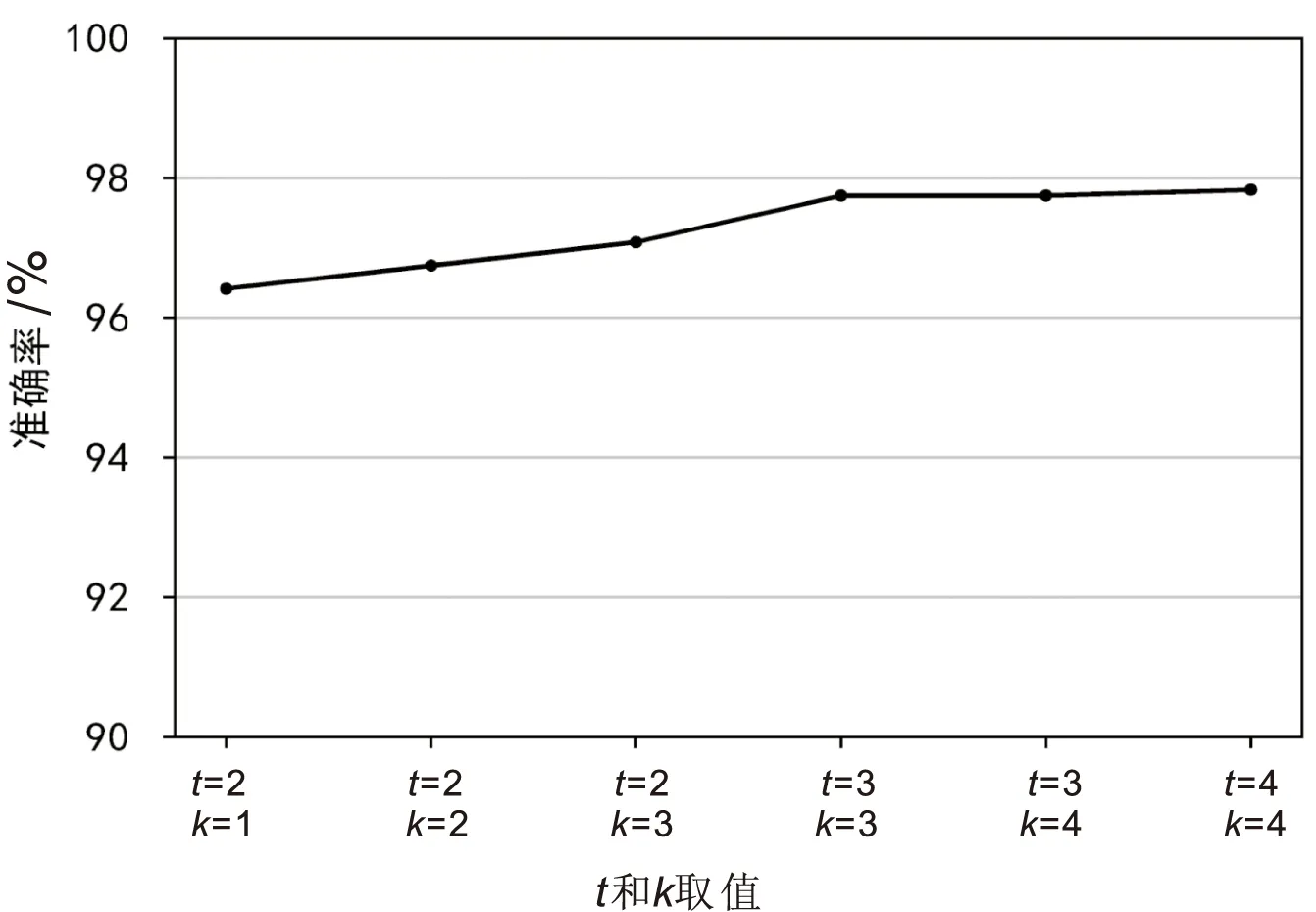
图6 t和k在不同数值下的准确率变化情况
由图6可以看到,随着t和k的增大,算法的准确率也在提高,当t=3和k=3,算法的准确率趋于平稳。因此,选择t=3和k=3作为BaggingCNN的最优参数,即子训练集个数为3,选取准确率前3的GoogLeNet[23]、ResNet[24]、DenseNet[25]作为子分类器,其具体参数如表2所示。

表2 子分类器具体参数
3.5 FIG-AMD方法有效性
在检测能力、学习能力和泛化能力方面进行对比实验,对FIG-AMD方法的有效性进行验证:
(1)检测能力。
为了验证FIG-AMD方法具备更好的检测能力,利用GoogLeNet、ResNet、DenseNet和多种机器学习算法设计恶意软件检测方法,并与FIG-AMD方法进行对比。其中,GoogLeNet、ResNet、DenseNet的输入为生成的特征图像,机器学习算法的输入为特征预处理阶段多特征融合的线性特征向量,各算法均经过参数调整优化,算法分类性能达到最佳,实验对比结果如表3所示。

表3 不同方法各项评估指标对比 %
从表3可以看到,GoogLeNet、ResNet、DenseNet的检测效果优于传统的机器学习方法,但检测效果仍不及该文提出的FIG-AMD方法。因此,FIG-AMD方法相比较于其它方法,具备更好的检测能力。
(2)学习能力。
为测试FIG-AMD方法的学习能力,改变FIG-AMD方法特征图像生成阶段生成的图像数目以及正常样本与恶意样本的比例,并使用BaggingCNN分类算法对生成的特征图像进行训练和分类,实验结果如图7所示。
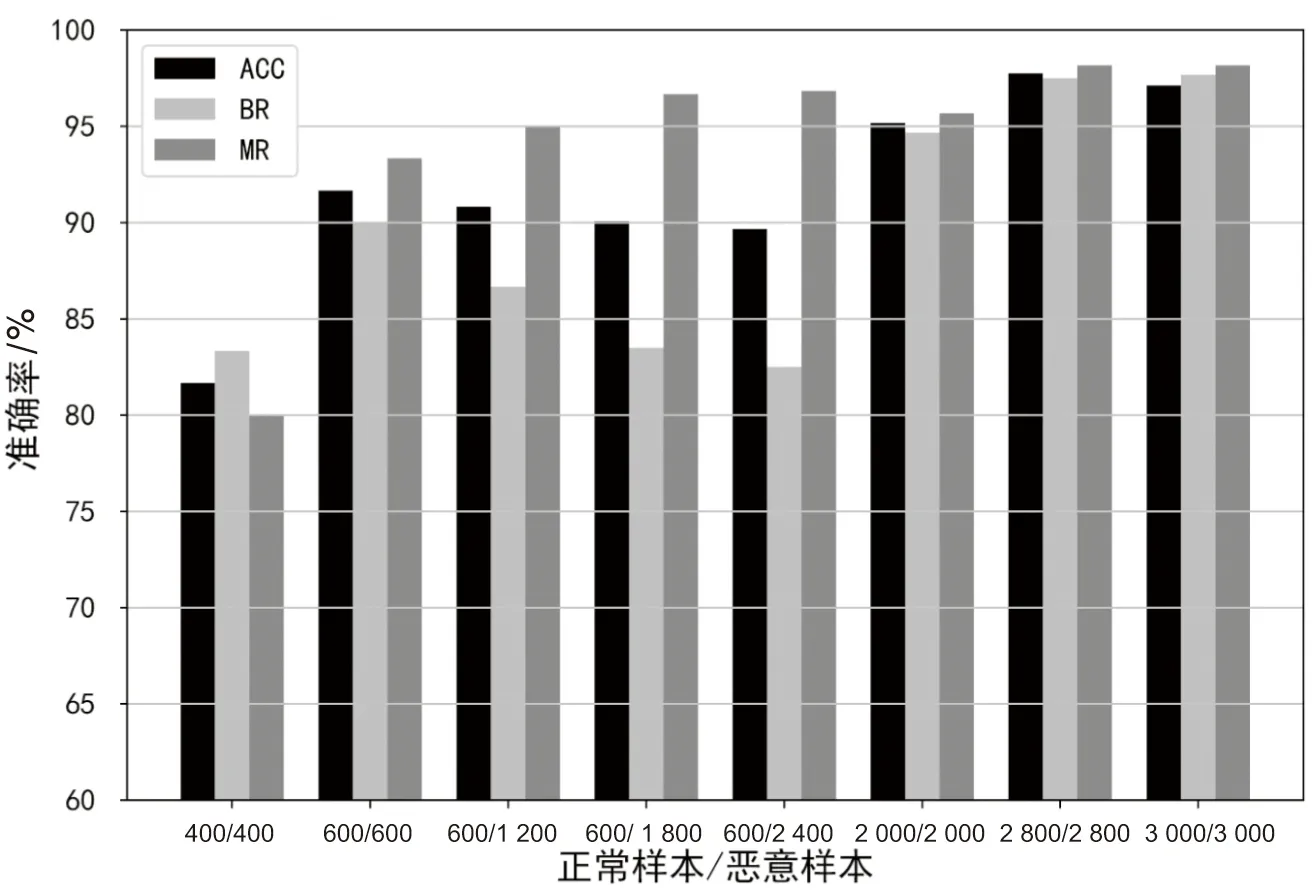
图7 不同比例和数目样本对FIG-AMD方法学习能力影响
从图7中可以看到,在样本分布不平衡或者样本数目较少时,FIG-AMD方法可以保持较高的检测准确率。当样本比例保持在1∶1时,FIG-AMD方法的良性召回率和正常召回率较为接近,随着样本总数的增加,其各项检测指标均在提高,说明FIG-AMD方法的学习能力在不断提高。因此,提出的FIG-AMD方法具有较强的学习能力,其可以有效地从少量样本或不平衡样本中学习到不同类别样本的特征。
(3)泛化能力。
在泛化能力测试方面,首先将文献[13,15,17,18]提出的方法和该文提出的FIG-AMD方法使用相同的数据集进行训练,再选用不同于该文训练集和测试集的600个样本(正常样本300个,恶意样本300个)进行测试。其中,文献[13]为使用APK文件动态行为特征构造的特征向量经过Stacking训练得到的分类结果;文献[15]为组件、Intent Filter等特征经过遗传算法筛选特征,使用DNN分类得到的结果;文献[17]为使用深度收缩自编码网络对多特征融合的特征向量分类的结果;文献[18]为dex文件转换成RGB图片,使用CNN分类的结果。此外,还将文献[18]的分类算法替换成BaggingCNN进行了实验,准确率得到了一定提升,说明BaggingCNN具有更好的分类性能,所有方法对比结果如表4所示,由表中对比结果可以看到:提出的FIG-AMD方法在准确率、误报率等指标方面,均优于其它检测方法,因此,可以认为FIG-AMD方法具备较强的泛化能力。
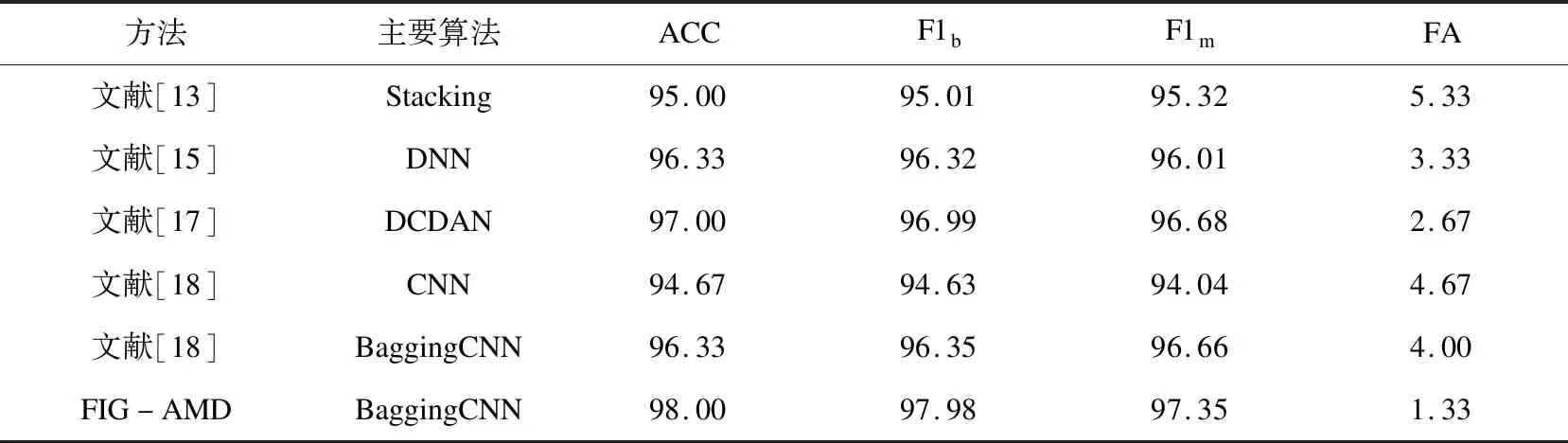
表4 不同方法检测性能对比 %
4 结束语
设计了FIG-AMD方法对Android恶意软件进行检测,该方法侧重于特征图像的生成,提取APK文件多种特征并挖掘相关性高的特征组合,引入降噪自编码器挖掘特征的深层信息和转换特征维度,生成特征图像用于训练和分类,解决了训练数据表征能力不足,影响分类算法收敛速度和检测精度的问题。在分类算法方面,将多个CNN分类器调整后集成在一起,基于Bagging算法思想,设计BaggingCNN分类算法,该算法解决了单一分类算法鲁棒性偏差的问题。经过实验证明,提出的FIG-AMD方法可以对Android恶意软件进行准确检测,并在误报率方面有着较大的降低,且该方法具有较好的学习能力和泛化能力。
在未来工作中,计划在检测方法中加入Android对抗样本检测机制,力求对设计的方法进行完善,从而可以准确检测普通Android样本以及Android对抗样本。





 人次
人次